In the realm of data management, the desire to store granular details about information, such as its origin and the individuals responsible for its collection, is a common and valuable objective. This pursuit often leads to intricate design decisions, particularly when dealing with relational databases. While traditional database schemas offer robustness and ease of querying for core data, the inclusion of metadata can introduce complexities. This article explores the challenges and potential solutions for effectively capturing metadata, focusing on the trade-offs between traditional relational design and more flexible, albeit potentially complex, approaches like the Entity-Attribute-Value (EAV) model. We will also delve into modern solutions that leverage AI and platform-specific features to automate and streamline metadata capture.
The Challenge of Tracking Data Provenance
Imagine a scenario where you are building a database for movies. The core attributes of a movie are straightforward: its title, director, leading male and female actors, and the villain. A well-designed relational table, let's call it Movies, would elegantly capture this information. However, you also want to track the source of each piece of data (e.g., a specific website, a published book, an interview) and the name of the journalist who discovered or verified that fact.
Initially, one might consider augmenting the Movies table by adding columns like Director_Source, Director_Journalist, LeadingMale_Source, LeadingMale_Journalist, and so on. While this approach directly associates metadata with the corresponding data point, it quickly becomes unwieldy and aesthetically unpleasing. The table would expand exponentially with each new piece of metadata to be tracked, leading to a wide and sparse table that is difficult to manage and query. This "ugliness" is a significant indicator of a potential design flaw.
Exploring the Entity-Attribute-Value (EAV) Model
The Entity-Attribute-Value (EAV) model presents an alternative for handling situations where the attributes of an entity can vary or where you need to store metadata about the attributes themselves. In an EAV model, you typically have three core tables:
- Entities: This table stores the primary objects (e.g., movies).
- Attributes: This table defines the properties that can be associated with entities (e.g., "Director," "Leading Male," "Source," "Journalist").
- Values: This table links entities to attributes and stores the actual data.
For our movie example, this might look like:
- Movies Table:
MovieID,Title - MovieAttributes Table:
AttributeID,AttributeName(e.g., "Director", "Source", "Journalist") - MovieValues Table:
MovieValueID,MovieID,AttributeID,Value
This structure, at first glance, seems to elegantly solve the problem of capturing metadata. You can easily add new attributes (like "Source" or "Journalist") without altering the core table structure. However, the EAV model comes with significant drawbacks, particularly concerning query complexity and data integrity.
The Pitfalls of EAV
The primary concern with EAV, as you've rightly identified, is the difficulty in querying. Retrieving all the basic data for a single movie becomes a complex operation, requiring multiple joins across the Movies, MovieAttributes, and MovieValues tables. Instead of a simple SELECT * FROM Movies WHERE MovieID = 123;, you'd be looking at a much more convoluted query.
Furthermore, EAV models are notoriously susceptible to data integrity issues. A critical weakness lies in the potential for decoupling data if attribute names change. If the "Villain" column in a traditional table were renamed to "Primary Villain," and if this renaming is not meticulously synchronized with the corresponding entry in the EAV's "attribute" column, the related data will become orphaned or misinterpreted. This fragility underscores the need for robust mechanisms to maintain consistency.
Mitigating EAV Weaknesses
To address the data integrity concerns associated with EAV, several improvements can be considered. One suggestion is to link the Attribute column to another table that acts as an enumeration of valid column names. This "enumeration table" would essentially serve as a master list of all possible attributes. The responsibility would then fall on the Database Administrator (DBA) to maintain this enumeration table, ensuring it accurately reflects the actual columns or attribute types in use.
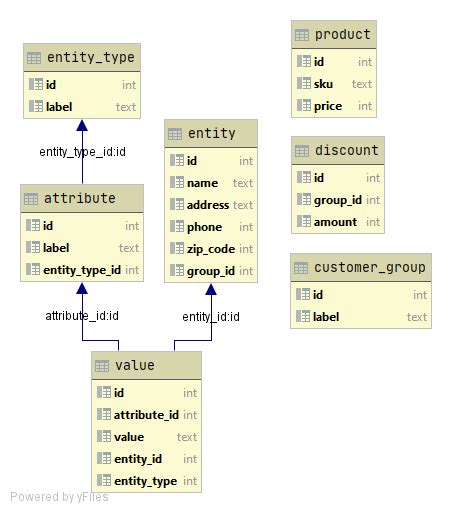
This approach can be further enhanced by automating the maintenance of this enumeration table. Instead of manual updates, it's possible to leverage system views within SQL Server (or equivalent features in other database systems) that provide information about the database's schema, including column names. By dynamically populating the enumeration table from such system views, the risk of manual errors and data decoupling is significantly reduced.
The Role of Metadata in Modern Platforms: SharePoint and AI
The challenges of managing metadata in traditional relational databases highlight the evolution of data management strategies. Modern platforms, particularly those within the Microsoft 365 ecosystem, offer sophisticated solutions for capturing and leveraging metadata, often powered by Artificial Intelligence (AI).
SharePoint, a platform designed for document management and collaboration, places a strong emphasis on metadata. Instead of relying solely on folder structures, SharePoint encourages the use of columns to capture descriptive information about files. This metadata enriches content, making it more discoverable and manageable.
AI-Powered Metadata Extraction in SharePoint
SharePoint, especially when integrated with Syntex (now part of Microsoft 365 Copilot), introduces powerful AI capabilities for metadata capture. This system can analyze files within a document library and intelligently suggest or automatically extract metadata.
The process typically involves:
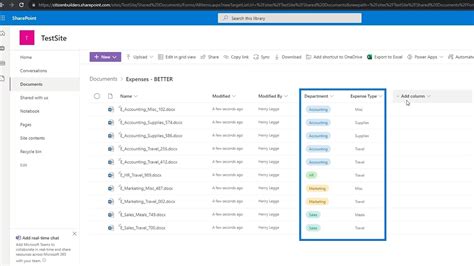
- Adding a Column: Users can add new columns to a SharePoint library to capture specific types of information.
- Autofill and AI Suggestions: A key feature is the "Autofill" option, powered by AI. When enabled, the system analyzes existing files to suggest relevant metadata columns and extraction prompts.
- Configuring Extraction Prompts: Users can define clear instructions for the AI, specifying the type of information to capture (e.g., "reason for document creation," "project rationale") and any desired format or length.
- Testing and Refinement: The AI's suggestions can be tested on a sample of files, allowing users to refine the extraction prompts to ensure accuracy.
- Automatic Processing: Once configured, AI-generated metadata columns can automatically process new files as they are uploaded. Existing files can also be processed in batches.
This AI-driven approach offers several advantages:
- Efficiency: It automates a labor-intensive process, saving significant time and effort.
- Consistency: AI can apply metadata consistently across a large number of documents.
- Discovery: It makes content more searchable by enriching it with relevant descriptive data.
Managed Metadata and Taxonomies
Beyond AI-driven extraction, SharePoint also supports "Managed Metadata." This involves creating structured groups of terms (term sets) that standardize vocabulary across the organization. Managed metadata columns allow users to select terms from these predefined lists, ensuring consistency and enabling more precise classification and retrieval of content.
- Term Sets: These are hierarchical collections of terms. For example, a "Project Status" term set might include terms like "Planning," "In Progress," "Completed," and "On Hold."
- Managed Metadata Columns: When added to a SharePoint list or library, these columns link to a specific term set, guiding users to select appropriate values.
This structured approach is crucial for building a robust taxonomy â a formal classification system that organizes information and makes it easily accessible.
Tagging in SharePoint: Managed Metadata vs. Choice Columns | Nested Choices
The "Source Only" Scenario: A Simpler Path?
Let's consider a simplified version of the original problem: you only need to track the "Source" of the data, without the "Journalist." The problematic approach of Director_Source, LeadingMale_Source, etc., still applies.
If the core data columns are relatively stable and predictable (e.g., always having "Director," "Leading Male," "Leading Female," "Villain"), the EAV model might still be considered, especially if the metadata is extensive. However, the inherent complexities of EAV querying and potential integrity issues remain.
If the metadata requirement is limited to a single aspect like "Source," and the core data structure is fixed, a hybrid approach could be explored. This might involve a MovieData table for core movie facts and a separate MovieMetadata table where each row links to a MovieID and stores a AttributeName (e.g., "Director") and its corresponding Source.
- MovieData Table:
MovieID,Title,Director,LeadingMale,LeadingFemale,Villain - MovieMetadata Table:
MetadataID,MovieID,AttributeName,Source
This still requires joins but might be more manageable than a full EAV for just one metadata attribute. However, it still doesn't fully address the "safety and accessibility" of storing metadata on the attributes themselves in a truly relational and robust manner.
Reconciling Relational Design with Metadata Requirements
The core tension lies in the desire for the simplicity and true RDBMS design of a well-structured table (like our initial Movies table) while simultaneously storing metadata about the attributes in a safe and accessible manner. This is a common design challenge, and the "best" solution often depends on the specific constraints and priorities of the project.
The Case for Well-Defined Schemas with Metadata Extensions
For scenarios where the core data attributes are stable and well-defined, a pragmatic approach often involves:
- A Solid Core Schema: Maintain a normalized, relational schema for the primary data. This ensures query performance and data integrity for the core attributes.
- Dedicated Metadata Tables: For metadata that needs to be tracked about specific attributes or values, create dedicated tables. These tables would link back to the core data tables. For instance, instead of
Director_Source, you might have aDirectorFactstable linked to theMoviestable, containing columns likeMovieID,Director,Source,Journalist,DateVerified, etc. This keeps the coreMoviestable clean while allowing for rich metadata. - Enumeration and Referential Integrity: As discussed with EAV, using enumeration tables for attribute names and enforcing referential integrity can prevent data decoupling.
- Views and Stored Procedures: Abstracting the complexity of joining core data with metadata through views and stored procedures can make querying more accessible for end-users.
The Evolving Landscape of Data Management
The rise of platforms like SharePoint, coupled with advancements in AI, offers compelling alternatives for metadata management. These systems are built with the explicit purpose of handling unstructured and semi-structured data, and their metadata capabilities are often more integrated and user-friendly than traditional relational approaches.
For organizations heavily invested in the Microsoft ecosystem, leveraging SharePoint's AI-powered metadata extraction and managed metadata features can be a highly effective strategy. These tools reduce the burden on DBAs and developers to manually manage metadata integrity and provide end-users with powerful search and organization capabilities.
The fundamental principle remains: metadata is crucial for understanding, organizing, and retrieving data. The challenge lies in choosing the right tools and strategies to capture and manage this metadata effectively, balancing the benefits of structured design with the flexibility required for comprehensive data context. The journey from manual column additions to sophisticated AI-driven extraction reflects the ongoing innovation in making data more accessible and meaningful.